
【翻译】 深入理解以太坊虚拟机 - 如何表示固定长度的数据类型
原文:https://medium.com/@hayeah/diving-into-the-ethereum-vm-part-2-storage-layout-bc5349cb11b7
译者:中山大学数学学院(珠海)林学渊
大二时给量子做的翻译,转载注明出处,谢谢
如何表示固定长度的数据类型
我是怎样学会了担忧以及计算存储成本
在本系列文章的第一篇中,我们看了一个简单 Solidity 合约的汇编代码:
1 | contract C { |
该合约实际上是调用了 sstore 指令:1
2// a = 1
sstore(0x0, 0x1)
- EVM 把值 0x1 保存在存储位置 0x0.
- 每个存储位置实际上能存 32 字节 (或者 256 比特).
如果对这个不熟,我建议看: Diving Into The Ethereum VM Part 1 — Assembly & Bytecode
在本篇文章中,我们关注 Solidity 如何使用32字节的块来表示更多复杂的数据类型,比如结构体和数组。我们也能看到如何优化存储,及怎样可能优化失败。
在典型的程序语言中,理解数据类型在底层如何表示不是特别有用。但在 Solidity (或任何 EVM 语言) 这种知识至关重要,因为存储访问太贵了。
sstore花费 20000 gas, 或者比基础算术指令贵约 5000倍.sload花费 200 gas, 或者比基础算术指令贵约 100倍.
对于“花费”,我们这里谈的是真钱,不仅仅是性能上的多少毫秒。运行和使用合约的花费中,sstore 和 sload 占主导地位!
磁带解析
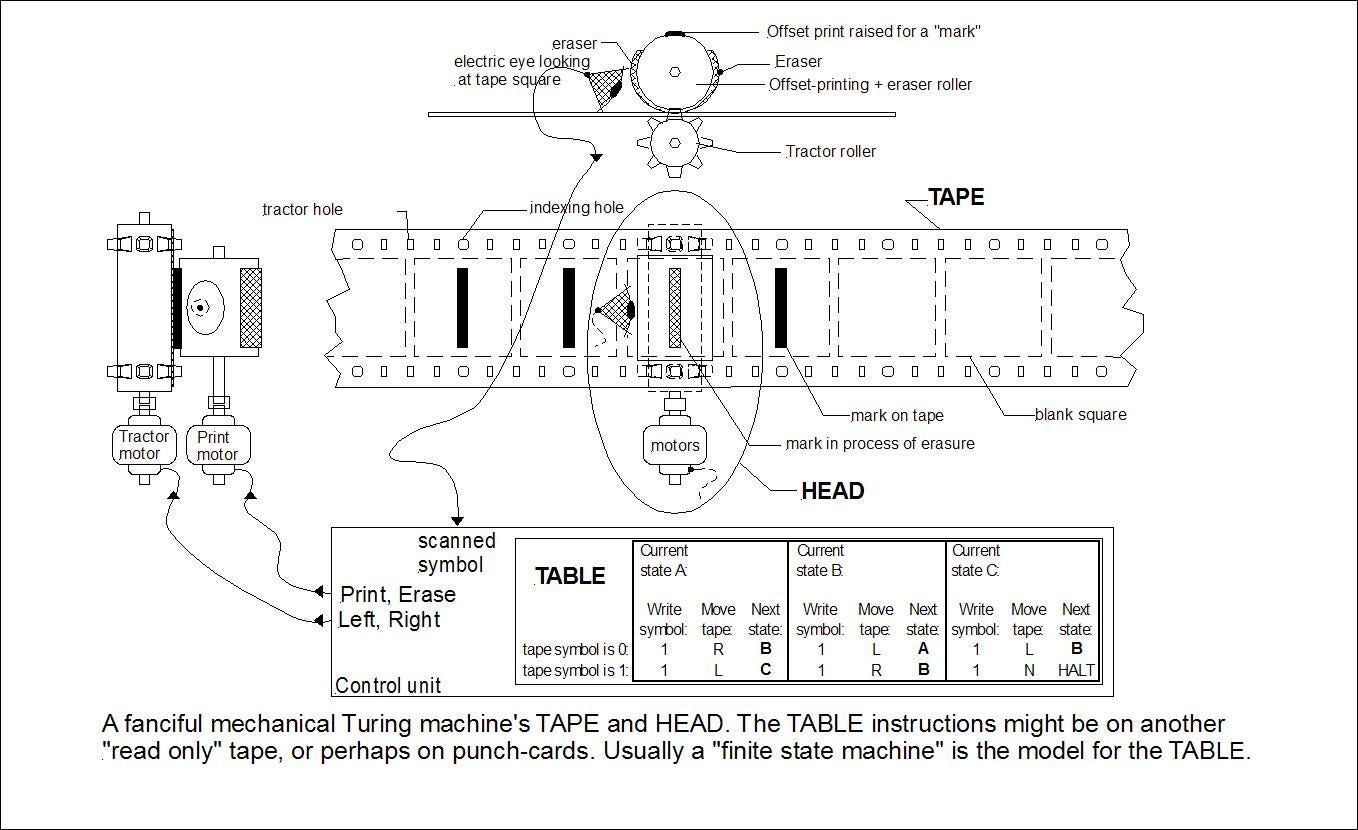
构建通用计算机的两个基本要素:
- 一种循环方式,无论是跳转还是递归。
- 无限内存
EVM 汇编代码提供跳转,EVM 存储提供无限内存。这些对一切都够用了,包括模拟一个运行以太坊的世界,其以太坊又模拟了一个运行以太坊的世界…

EVM 存储一个合约像是一条没有尽头的磁带,磁带的每个单元有32字节,像这样:1
[32 字节][32 字节][32 字节]...
我们会看到数据如何在无尽的磁带上变得生动起来的。
磁带长度为 2²⁵⁶, 或者每个合约有大约10⁷⁷个单元。宇宙的可观测的粒子数是10⁸⁰。大约1000个合约就足以容纳所有质子,中子和电子。不要相信营销炒作,因为它比无限更短。
空白磁带
存储最初是空白的,默认为 0 。拥有无限磁带并不需要花费任何东西。
我们来看一个简单的合约来说明零价值行为:1
2
3
4
5
6
7
8
9
10
11
12pragma solidity ^0.4.11;
contract C {
uint256 a;
uint256 b;
uint256 c;
uint256 d;
uint256 e;
uint256 f;
function C() {
f = 0xc0fefe;
}
}
存储中的布局很简单。
- 变量
a位于位置0x0 - 变量
b位于位置0x1 - 如此下去…
关键问题: 如果我们只用f, 我们给a,b,c,d,e花多少?
编译看一下:1
$ solc --bin --asm --optimize c-many-variables.sol
汇编:1
2
3
4
5// sstore(0x5, 0xc0fefe)
tag_2:
0xc0fefe
0x5
sstore
因此,存储变量的声明不需要任何费用,因为没有初始化。 Solidity 为该变量保留一个位置,并且只有当你存储某些内容时才支付 gas 。
在这种情况下,我们只为存储到 0x5 花钱。
如果我们手工编写汇编,我们可以任意选择存储位置而不必“扩展”存储:
1 | // 写入任意位置 |
读取 0
你不仅可以在存储的任何位置写入,还可以立即从任何位置读取。读取未初始化的位置仅返回 0x0 。
让我们看一个读取未初始化位置的合约:
1 | pragma solidity ^0.4.11; |
编译:1
$ solc --bin --asm --optimize c-zero-value.sol
汇编代码:1
2
3
4
5
6
7
8
9
10
11tag_2:
// sload(0x0) returning 0x0
0x0
dup1
sload
// a + 1; where a == 0
0x1
add
// sstore(0x0, a + 1)
swap1
sstore
注意:生成从未初始化位置加载数据的代码是有效的。
然而,我们可以比 Solidity 编译器更聪明。由于我们知道tag_2是构造函数,并且从未写入过,所以我们可以用0x0替换sload序列。这可以省 5,000 gas。
结构体的表示
我们来看第一个复杂数据类型,一个有 6 个字段的结构体:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15pragma solidity ^0.4.11;
contract C {
struct Tuple {
uint256 a;
uint256 b;
uint256 c;
uint256 d;
uint256 e;
uint256 f;
}
Tuple t;
function C() {
t.f = 0xC0FEFE;
}
}
存储中的布局和状态变量一样。
- 变量
t.a位于位置0x0 - 变量
t.b位于位置0x1 - 如此下去…
和之前类似,我们可以直接向 t.f 写入而不用给初始化花钱。
编译:1
$ solc --bin --asm --optimize c-struct-fields.sol
我们看到了一样的汇编代码:1
2
3
4tag_2:
0xc0fefe
0x5
sstore
定长数组
声明一个定长数组:1
2
3
4
5
6
7pragma solidity ^0.4.11;
contract C {
uint256[6] numbers;
function C() {
numbers[5] = 0xC0FEFE;
}
}
由于编译器确切地知道有多少个 uint256 ( 32 个字节),因此它可以简单地将数组元素放在存储器中,就像存储变量和结构体一样。
在这份合约中,我们再次存储到位置 0x5 。
编译:1
$ solc --bin --asm --optimize c-static-array.sol
汇编代码:1
2
3
4
5
6
7
8
9
10tag_2:
0xc0fefe
0x0
0x5
tag_4:
add
0x0
tag_5:
pop
sstore
它稍微长一些,但如果你稍微眯起一点,你会发现它实际上是一样的。我们手动进一步优化:1
2
3
4
5
6
7
8
9
10tag_2:
0xc0fefe
// 0+5. 用 0x5 代替
0x0
0x5
add
// Push then pop immediately. Useless, just remove.
0x0
pop
sstore
除去标签和伪指令,我们再次得到相同的字节码序列:1
2
3
4tag_2:
0xc0fefe
0x5
sstore
数组边界检测
我们已经看到,定长数组与结构体或状态变量两者具有相同的存储布局,但生成的汇编代码是不同的。原因是 Solidity 为数组访问生成了边界检查。
让我们再次编译数组合约,这次先关闭优化:1
$ solc --bin --asm c-static-array.sol
注释一下,在每条指令后打印机器状态:
1 | tag_2: |
现在可以看到边界检测代码了。编译器能够优化这些东西,但并不完美。
在本文的后面,我们将看到数组边界检测如何干扰编译器的优化,使得定长数组比存储变量或结构的效率低得多。
打包行为
存储很贵(啊啊啊我已经说一百万次了)。一个关键的优化是尽可能多地将数据打包到一个 32 字节的单元中。
考虑有四个存储变量(每个 64 比特)的合约,总共可以累加到 256 比特( 32 字节):
1 | pragma solidity ^0.4.11; |
我们希望编译器只用一个 sstore ,所以将它们放在同一个存储单元中。
编译:1
$ solc --bin --asm --optimize c-many-variables--packing.sol
汇编代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31tag_2:
/* "c-many-variables--packing.sol":121:122 a */
0x0
/* "c-many-variables--packing.sol":121:131 a = 0xaaaa */
dup1
sload
/* "c-many-variables--packing.sol":125:131 0xaaaa */
0xaaaa
not(0xffffffffffffffff)
/* "c-many-variables--packing.sol":121:131 a = 0xaaaa */
swap1
swap2
and
or
not(sub(exp(0x2, 0x80), exp(0x2, 0x40)))
/* "c-many-variables--packing.sol":139:149 b = 0xbbbb */
and
0xbbbb0000000000000000
or
not(sub(exp(0x2, 0xc0), exp(0x2, 0x80)))
/* "c-many-variables--packing.sol":157:167 c = 0xcccc */
and
0xcccc00000000000000000000000000000000
or
sub(exp(0x2, 0xc0), 0x1)
/* "c-many-variables--packing.sol":175:185 d = 0xdddd */
and
0xdddd000000000000000000000000000000000000000000000000
or
swap1
sstore
有很多我无法破译的位交换,但不用在意这些细节。关键要注意的是,只用了一个 sstore。
优化成功!
打破优化
要是优化器可以一直完美工作就好了。让我们打破它。我们唯一的改变是我们使用帮助函数来设置存储变量:
1 | pragma solidity ^0.4.11; |
编译1
$ solc --bin --asm --optimize c-many-variables--packing-helpers.sol
汇编输出太多了。我们将忽略大部分细节并关注结构:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// 构造函数
tag_2:
// ...
// 跳转到 tag_5,调用 setAB()
jump
tag_4:
// ...
// 跳转到 tag_7,调用 setCD()
jump
// 函数 setAB()
tag_5:
// 位交换,设置 a, b
// ...
sstore
tag_9:
jump // 返回 setAB() 的调用者
// 函数 setCD()
tag_7:
// 位交换,设置 c, d
// ...
sstore
tag_10:
jump // 返回 setCD() 的调用者
现在有两个 sstore ,而不是一个。 Solidity 编译器可以在标签内进行优化,但不能跨标签进行优化。
调用函数可能会花费更多,而不是太多,不仅因为函数调用很贵(它们只是跳转指令),而且因为
sstore优化可能会失败。
为了解决这个问题, Solidity 编译器需要学习如何内联函数,使得本质上得到的代码与不调用函数的相同:
1 | a = 0xaaaa; |
如果我们仔细阅读完整的汇编输出,我们会看到函数 setAB()和 setCD()的汇编代码被包含了两次,使代码臃肿,还花费额外 gas 部署合约。我们稍后在了解合约生命周期时再讨论这一点。
为什么优化器坏了
优化器不会跨标签进行优化。考虑 “1 + 1” ,如果在同一标签下,它可以优化为 0x2 :1
2
3
4
5
6// 优化成功!
tag_0:
0x1
0x1
add
...
但会优化失败,如果指令被标签分开了的话:1
2
3
4
5
6
7// 优化失败!
tag_0:
0x1
0x1
tag_1:
add
...
这个行为在 0.4.13 版时是真的。以后可能会变。
再次打破优化
让我们看看优化失败的另一种方式。打包是否适用于定长数组?考虑:1
2
3
4
5
6
7
8
9
10pragma solidity ^0.4.11;
contract C {
uint64[4] numbers;
function C() {
numbers[0] = 0x0;
numbers[1] = 0x1111;
numbers[2] = 0x2222;
numbers[3] = 0x3333;
}
}
同样,我们希望只用一个 sstore 指令将 4 个 64 比特的数字打包到一个 32 字节的存储单元中。
编译后的汇编代码太长了。作为替代,计算 sstore 和 sload 指令的数量:1
2
3
4
5
6
7
8
9$ solc --bin --asm --optimize c-static-array--packing.sol | grep -E '(sstore|sload)'
sload
sstore
sload
sstore
sload
sstore
sload
sstore
嗷!不!!即使这个定长数组的存储布局与等效的结构体或存储变量完全相同,优化也会失败。它现在需要四对 sload 和 sstore 。
快速浏览汇编代码可以发现,每个数组访问都有边界检测代码,并在不同的标签下进行组织。但标签边界打破了优化。
然而有一点小小的安慰的是,3 个额外的 sstore 指令比第一个便宜:
sstore花费 20,000 gas用于第一次写入新位置。sstore花费 5,000 gas用于后续写入现有位置。
所以这个特定优化的失败花费我们 35k 而不是 20k ,多了 75% 。
小结
如果 Solidity 编译器能够计算出存储变量的大小,它只须简单地将它们放在一个接一个的存储空间中。如果可能的话,编译器将数据紧密地打包成32字节的块。
总结我们目前为止看到的打包行为:
- 存储变量:有。
- 结构字段:有。
- 定长数组:无。理论上,有。
由于存储访问成本非常高,因此应该将存储变量视为数据库架构。在编写合约时,可能会很有用的是做小型实验,并检查汇编代码以确定编译器是否正在优化。
可以肯定, Solidity 编译器将来会有所改进。不幸的是,现在我们还不能盲目信任它的优化器。
理解存储变量要花钱,字面意思,花钱。