
【Android TimeCat】 让Android-Studio快十倍
背景
Android Studio 越用越卡,明明电脑配置不低了。。。
原因分析
Android Studio 是Java写的软件,运行在Java虚拟机上,如果使用时间长,会频繁触发垃圾回收机制,导致卡顿。
解决方法
配置Android Studio,给它分多点内存。给2048m应该够用了,如果不够,再来4096m.
解决思路
配置Android Studio,给它分多点内存。
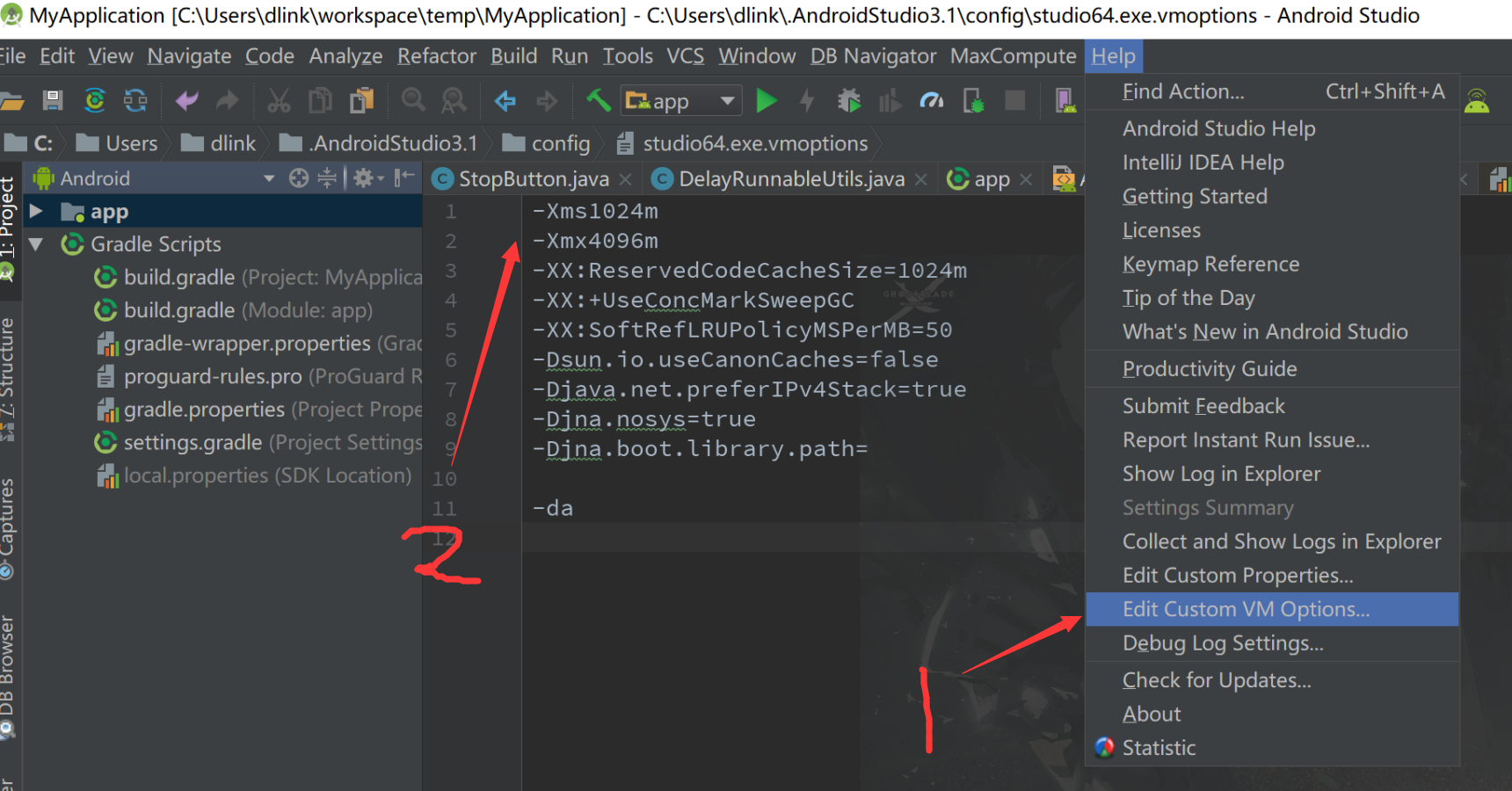
Android Studio 通过 Help 菜单提供对两个配置文件的访问:
studio.vmoptions:自定义 Studio Java 虚拟机 (JVM) 的选项,如堆内存和缓存大小。请注意,对于 Linux 机器,此文件可能命名为 studio64.vmoptions,具体取决于您的 Android Studio 版本。idea.properties:自定义 Android Studio 的属性,如插件文件夹路径或最大支持文件大小。
自定义 VM 选项
通过 studio.vmoptions 文件,您可以自定义适用于 Android Studio 的 JVM 的选项。为了提高 Studio 的性能,最常用的调节选项是最大堆内存,但您也可以使用 studio.vmoptions 文件替换其他默认设置,如初始堆内存、缓存大小和 Java 垃圾回收开关。
要新建 studio.vmoptions 文件或打开现有文件,请执行以下步骤:
点击 Help > Edit Custom VM Options。如果您之前从未编辑过适用于 Android Studio 的 VM 选项,IDE 将提示您新建一个 studio.vmoptions 文件。点击 Yes 创建文件。
此时 studio.vmoptions 文件将在 Android Studio 的编辑器窗口中打开。编辑文件以添加您自己的自定义 VM 选项。如需可自定义 JVM 选项的完整列表,请参阅 Oracle 的 Java HotSpot VM 选项页。
您创建的 studio.vmoptions 文件将添加至默认 studio.vmoptions 文件,后者位于 Android Studio 安装文件夹内的 bin/ 目录中。
请注意,切勿直接编辑 Android Studio 程序文件夹内的 studio.vmoptions 文件。尽管您可以访问该文件来查看 Studio 的默认 VM 选项,但仅编辑自己的 studio.vmoptions 文件可确保您不会替换 Android Studio 的重要默认设置。因此,在您的 studio.vmoptions 文件中,请仅替换您关注的属性,使 Android Studio 可以继续使用未更改的任何属性的默认值。
最大堆内存
默认情况下,Android Studio 的最大堆内存为 1280MB。如果您要处理大项目,或者您的系统有大量 RAM 可用,您可以通过在 Android Studio 的 VM 选项中增加最大堆内存来提高性能。如果系统的内存有限,您可能希望降低最大堆内存。
要更改最大堆内存,请执行以下步骤:
点击 Help > Edit Custom VM Options 以打开您的 studio.vmoptions 文件。
向 studio.vmoptions 文件添加一个行,使用语法 -XmxheapSize 设置最大堆内存。您选择的大小应该基于项目大小以及机器上的可用 RAM。作为基准,如果您有 4GB 以上的 RAM 和中等大小的项目,则应该将最大堆内存设置为 2GB 或更高。以下行可将最大堆内存设置为 2GB:1
-Xmx2g
保存对 studio.vmoptions 文件所做的更改,然后重新启动 Android Studio 以使更改生效。
#
从AndroidStudio的启动参数了解到的下JVM的一些东西(内存使用,JIT等)
如果你使用AndroidStudio经常觉得很卡,那有可能是因为系统给AS分配的内存不够的原因。打开/Applications/Android Studio.app/Contents/bin/studio.vmoptions (Mac),可以看到有以下配置:1
-Xms128m -Xmx750m -XX:MaxPermSize=350m -XX:ReservedCodeCacheSize=96m -XX:+UseCompressedOops
这些参数分别是什么意思呢?
-Xms128m
1 | The -Xms option sets the initial and minimum Java heap size. The Java heap (the “heap”) is the part of the memory where blocks of memory are allocated to objects and freed during garbage collection. |
就是JVM启动的起始堆内存,堆内存是分配给对象的内存。这里我把它改成了512m
-Xmx750m
1 | This option sets the maximum Java heap size. |
也就是AndroidStudio能使用的最大heap内存,这里我改成了2048m
这两个参数都是-X开头的,表示非标准的参数。什么叫非标准的呢?我们知道JVM有很多个实现,Oracle的,OpenJDK等等,这里的-X参数,是Oracle的JVM实现使用的,OpenJDK不一定能使用,也就是没有将这些参数标准化,让所有的JVM实现都能使用。
-XX:MaxPermSize=350m
这个参数指定最大的Permanent generation大小。
根据oracle的文档:1
Permanent Generation (non-heap): The pool containing all the reflective data of the virtual machine itself, such as class and method objects. With Java VMs that use class data sharing, this generation is divided into read-only and read-write areas.
可知,Permanent Generation也是一块内存区域,跟heap不同,它里面存放的事类本身(不是对象),以及方法,一些固定的字符串等等。更多关于Permanent Generation
-XX:ReservedCodeCacheSize=90m
1 | ReservedCodeCacheSize (and InitialCodeCacheSize) is an option for the (just-in-time) compiler of the Java Hotspot VM. Basically it sets the maximum size for the compiler's code cache. |
设置JIT java compiler在compile的时候的最大代码缓存。简单地说就是JIT(Just In Time)编译器在编译代码的时候,需要缓存一些东西,这个参数指定最多能使用多大内存来缓存这些东西。
什么叫JIT呢?看wikipedia的解释:1
In computing, just-in-time compilation (JIT), also known as dynamic translation, is compilation done during execution of a program – at run time – rather than prior to execution.Most often this consists of translation to machine code, which is then executed directly, but can also refer to translation to another format. JIT compilation is a combination of the two traditional approaches to translation to machine code – ahead-of-time compilation (AOT), and interpretation – and combines some advantages and drawbacks of both.[1] Roughly, JIT compilation combines the speed of compiled code with the flexibility of interpretation, with the overhead of an interpreter and the additional overhead of compiling (not just interpreting). JIT compilation is a form of dynamic compilation, and allows adaptive optimization such as dynamic recompilation – thus in principle JIT compilation can yield faster execution than static compilation. Interpretation and JIT compilation are particularly suited for dynamic programming languages, as the runtime system can handle late-bound data types and enforce security guarantees.
我们知道编程语言分两种: - 编译型,先将人写的代码整个编译成汇编语言或机器语言,一条一条代码然后执行。 - 解释型,不需要编译,将人写的代码一条一条拿过来一次执行,先取一条,执行,完了再取下一条,然后在执行。
而对于Java来说,这个情况就比较特殊了,因为在Java这里,JVM先是将Java代码整个编译成bytecode,然后在JVM内部再一条一条执行bytecode代码。你说它是编译型的吧,bytecode又不用编译成机器代码,二是一条条bytecode一次执行。你说它是解释型的吧,它又有一个编译的过程。对于Java到底是编译型还是解释型到现在也没有一个定论。不过,我们还是可以探讨一下Java的JIT编译技术。
刚刚说了,在bytecode层面,代码是解释执行的。解释型的语言会比较慢,因为它没有办法根据上下文对代码进行优化。而编译型的语言则可以进行优化。Java的JIT技术,就是在bytecode解释执行的时候,它不一定是一条条解释执行的,二是取一段代码,编译成机器代码,然后执行,这样的话就有了上下文,可以对代码进行优化了,所以执行速度也会更快。
可见,JIT技术结合了编译型(速度更快)和解释型语言(代码更灵活)二者的优势。对于动态语言的执行来说,是一个非常大的优势。
-XX:+UseCompressedOops
这个参数允许系统将代码里面的引用(reference)类型用32位存储,同时却能够让引用能够使用64位的内存大小。
我们知道现代的机器基本都是64位的,在这种情况下,Java代码里面的reference类型也变成了用64位来存储,这就导致了两个问题:
64位比32为更大,占的内存更多,这是显然的,当然这个问题在整个程序看来根本不显然,因为哪怕系统同时有1000个引用存在,那多出来的内存也就4M,这个不重要,因为现在手机都动不动好几个G,大型服务器就更加不用说了。更重要的是第二点。
相对于内存,CPU的cache就小的可怜了,当reference从32bit变成64bit时,cache里面能存放的reference数量就顿时少了很多。所以64bit的reference对cache是个大问题,于是就有了这个选项,可以允许系统用32bit来存储reference,让cache里面能存放更多的reference,同时又不影响reference的取址范围。至于他们是怎么做到的,我就不得而知了。。。
以上三个参数是以-XX开头的,根据Oracle的说明,1
Options that are specified with -XX are not stable and are subject to change without notice.