
网页排序算法(一)PageRank
参加数学建模的时候要研究一下PageRank,为了巩固3天从入门到精通的成果,把了解到的整理成文。
直观理解
基本思想
PageRank是以Google创始人Larry Page的姓命名的,于1999被提出来,用于测量网页的相对重要性(对网页进行排序),学术论文如下:
Page, L., Brin, S., Motwani, R., & Winograd, T. (1999). The PageRank citation ranking: Bringing order to the web. Stanford InfoLab. [PDF]
PageRank的设计受到学术论文引用启发(两人的父亲都是大学教授)。衡量一篇学术论文质量高与否,最重要的一个指标是引用次数,高引用量的论文通常意味着高质量。同理,如果一张网页被引用(以超链接的形式)多了,那么这张网页就比较重要。总结起来,PageRank的核心思想有两点(结合图1说明):
- 越多的网页链接到一个网页(可以理解成投票,
D --> B,D给B投了一票),说明这个网页更加重要,如图1的B。(一篇论文被很多论文引用) - PageRank高的网页链接到一个网页,说明这张网页也很重要。如图1,尽管C只有一张网页B链接到它,但C的重要性高于E,尽管E有一堆小罗罗给它投票。(论文被大牛引用了,说明这篇论文很有价值)(也可以从话语权角度理解,重要的人说话份量重)
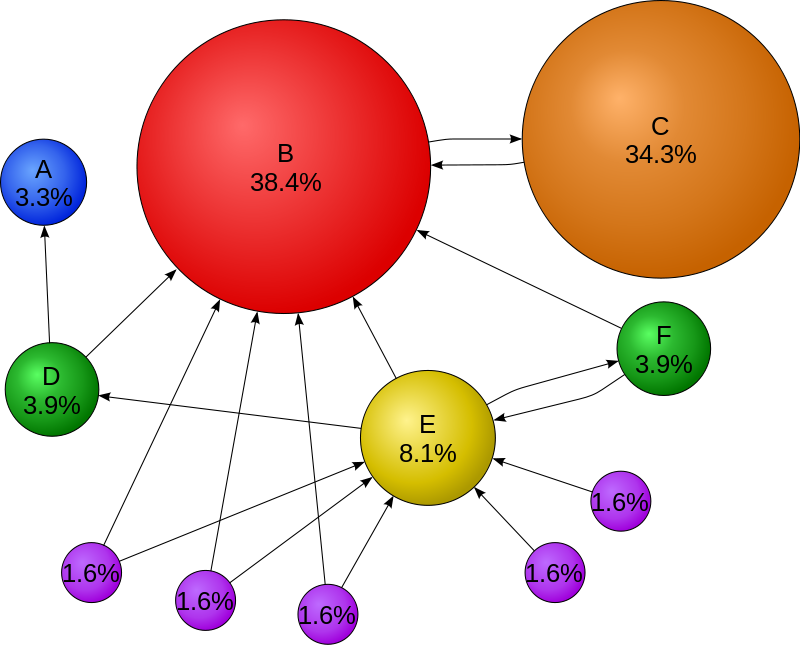
整个万维网(World Wide Web)可以抽象成一张有向图,节点表示网页,连线$$p_i\to p_j$$表示网页$$p_i$$包含了超链接$$p_j$$($$p_i$$指向了$$p_j$$)。如果能对图中每个节点重要性量化,那么就能对网页进行排序了。PageRank提出之初就是为了对网页进行排序。
搜索引擎的工作原理可以简化为:输入关键词,返回与该关键词相关的网页(一个集合,相当于得到一张子图),在该子图上计算每个节点的PageRank值,PR值高的网页排在前面,低的就排在后面。
如何计算
接下来的问题是,如何计算每个节点的PageRank。想要知道一个网页$$p_i$$的PR值,需要知道:
- 有多少网页链接到了$$p_i$$
- 这些网页的PR值是多少
其他网页的PR值又很可能是依赖于$$p_i$$,这就陷入了“先有鸡还是先有蛋”的循环,要想知道$$p_i$$的PR值,就得知道链向$$p_i$$所有网页的PR值,而要知道其他网页的PR值,又得先知道$$p_i$$的PR值。
为了打破这个循环,佩奇和布林采用了一个很巧妙的思路, 即分析一个虚拟用户在互联网上的漫游过程。 他们假定:虚拟用户一旦访问了一个网页,下一步将以相同的概率访问被该网页所链接的任何一个其它网页[3]。比如,网页$$p_i$$包含N个超链接,那么虚拟用户访问这N个页面中的任何一个的概率是1/N。那么,网页的排序就可以看成一个虚拟用户在万维网漫游了很长时间,页面被访问的概率越大,其PR值就越高,网页排名也越靠前。
先从简化的PageRank说起,以PageRank论文的例子为例,看看PageRank是怎么计算的,如下:
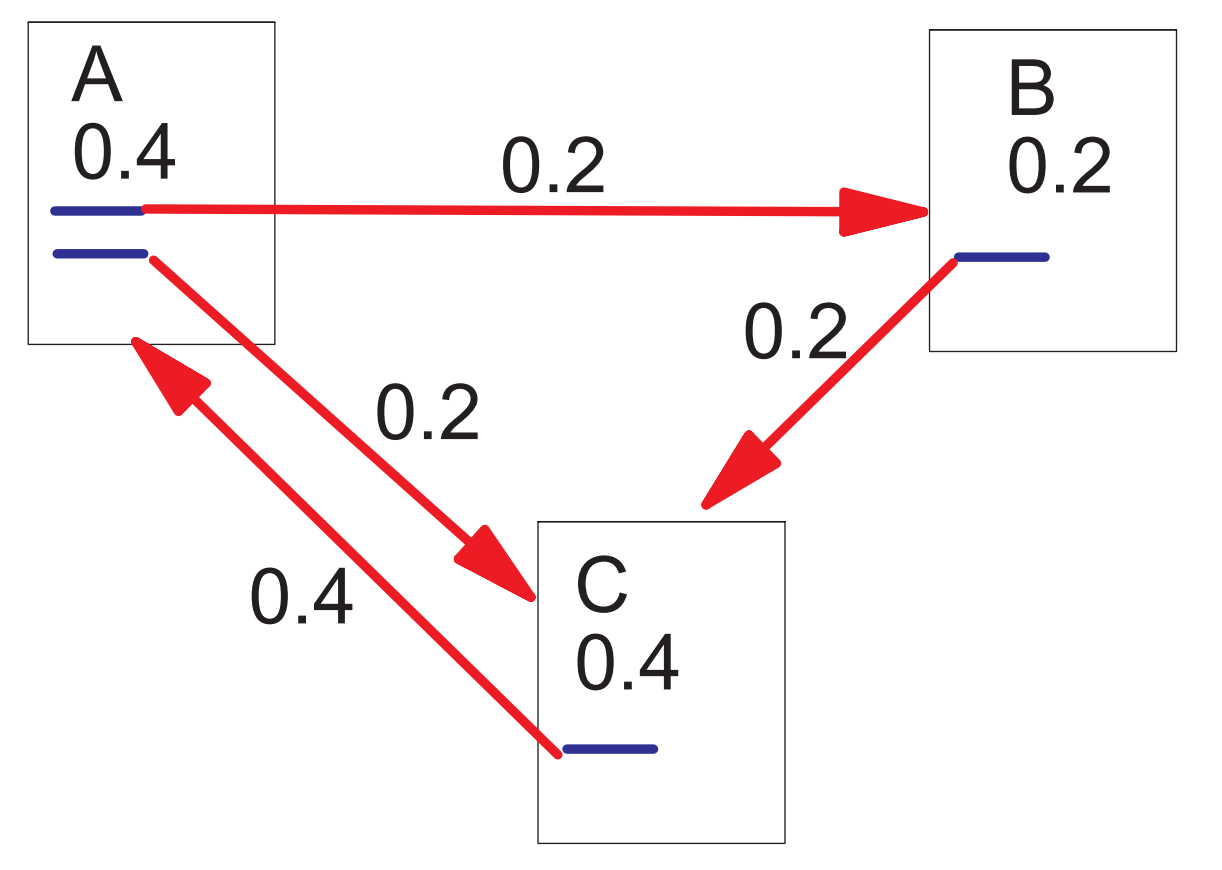
每个节点初始化或者指定一个PageRank值(如PR(A)=0.4),网页A包含两个超链接,分别指向B和C(或者说A投票给B和C),0.4拆分成两份,每份0.2,所以PR(B)=0.2。A和B同时给C投票,所以PR(C)=0.2+0.2=0.4。如此,不断地迭代,最后每个节点的值会趋于稳定(或者说收敛),这样就求得了所有节点的PR值。事实上,在这个例子中,PageRank已收俭。
每个页面将其当前的PageRank值平均分配到本页面所有出链上,一个页面将所有入链的PR值累加起来就构成了该页面新的PR值。如此迭代下去,最后得到一个稳定值。用数学公式表达,如下:
$$PR(A)=\frac{PR(B)}{L(B)}+\frac{PR(C)}{L(C)}+\frac{PR(D)}{L(D)}+⋯$$
更一般化地($$B(p_i)$$表示所有链向网页$$p_i$$的集合),
$$PR(pi)=\sum_{p_j\in B(p_i)}\frac{PR(p_j)}{L(p_j)}$$
但这样算存在两个问题:
- 对于没有forward links (outedges)的网页,即只有别人给她投票,她从不给别人投票,那么她的PageRank每次迭代都会增加。
- 对于没有blacklinks (inedges)的网页,即没人给她投票,其PageRank永远等于0。
对于第一个问题,给等式乘以一个小于1的常数d(damping factor,翻译成阻尼因数?);对于第二个问题,给等式加上一个常数。新的等式如下(N表示网页总数,或者节点数目):
$$PR(pi)=\frac{1−d}{N}+d\sum{p_j\in B(p_i)}\frac{PR(p_j)}{L(p_j)}$$
其中,
- $$B(p_i)$$:链接到网页pipi的集合(a set of pages link to pipi)
- $$L(p_j)$$:从$$p_j$$链出去的网页数目(the number of outbound links)
这样,就确保所有节点的PR值加起来等于1。
一个简单实例
以一个很简单的例子(A < --> B)来看PageRank是怎么收俭的。
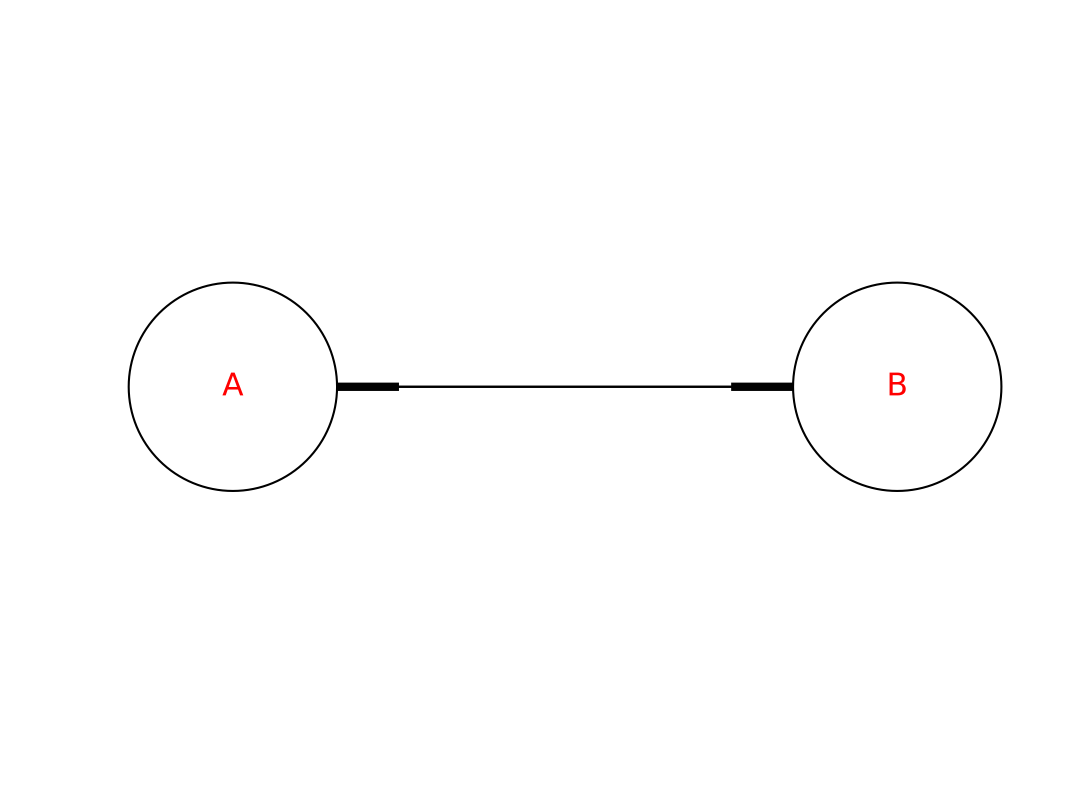
假设他们的初始PR值为1,第一次迭代后,PR(A)和PR(B)的值为:1
2PR(A) = 0.15/2 + 0.85*1.0 = 0.9249999999999999
PR(B) = 0.15/2 + 0.85*0.9249999999999999 = 0.8612499999999998
写个简单的Python脚本,得到每次迭代后的值,部分如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25 1: A=0.925000 B=0.861250
2: A=0.807062 B=0.761003
3: A=0.721853 B=0.688575
4: A=0.660289 B=0.636245
5: A=0.615808 B=0.598437
6: A=0.583672 B=0.571121
7: A=0.560453 B=0.551385
8: A=0.543677 B=0.537126
9: A=0.531557 B=0.526823
10: A=0.522800 B=0.519380
11: A=0.516473 B=0.514002
12: A=0.511902 B=0.510116
13: A=0.508599 B=0.507309
14: A=0.506213 B=0.505281
15: A=0.504489 B=0.503815
16: A=0.503243 B=0.502757
17: A=0.502343 B=0.501992
18: A=0.501693 B=0.501439
19: A=0.501223 B=0.501040
20: A=0.500884 B=0.500751
...
42: A=0.500001 B=0.500001
43: A=0.500001 B=0.500000
44: A=0.500000 B=0.500000
45: A=0.500000 B=0.500000
可见,随着迭代次数的增加,PageRank越来越接近收俭值0.5。Python源代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13def pagerank_ab():
"""
Calculate PageRank for A <--> B
"""
pr = {'A':1.0, 'B':1.0}
max_iter = 50
for idx in range(1, max_iter+1):
pr['A'] = 0.15/2 + 0.85*pr['B']
pr['B'] = 0.15/2 + 0.85*pr['A']
s = '{:3d}: A={:<10f}\tB={:<10f}'.format(idx, pr['A'], pr['B'])
print(s)
迭代次数
迭代次数越多,结果越准确,但花费时间也越长。出于效率考虑,在实际应用中,当PR值落在误差允许范围内(PR值跟前一次比较,如PR′(A)−PR(A)<1.0e−6PR′(A)−PR(A)<1.0e−6,想想浮点数在计算机的存储),就可以返回结果了。
Python实现的nx.pagerank相关源代码如下:1
2
3
4# check convergence, l1 norm
err = sum([abs(x[n] - xlast[n]) for n in x])
if err < N*tol: # tol=1.0e-6
return x
当然,对于超大型网络来说,有更复杂的计算方法,比如分布式。
PR初始值
不管节点PR初始值怎么设置,最后节点的PR值都一样,但收俭速度不一样。可以修改上面Python代码的PR初始值,运行代码,自行感受下。NetworkX的pagerank实现是将PR值初始化为1/N。
Damping factor
跟PR初始值类似,d的取值也会影响算法效率。根据Page的论文,d通常设为0.85。
PageRank计算方法
(1) 迭代方法
详情见另一篇博文《网页排序算法(二)迭代方法求PageRank》。
(2)代数方法
详情见另一篇博文《网页排序算法(三)代数方法求PageRank》。
(3)Power Method
待续。
用NetworkX求PageRank
NetworkX提供3个求PageRank的API,如下:
- pagerank(…)
- pagerank_numpy(…)
- pagerank_scipy(…)
详细API如下:
1 | pagerank(G, alpha=0.85, personalization=None, max_iter=100, tol=1e-06, nstart=None, weight='weight', dangling=None) |
References: