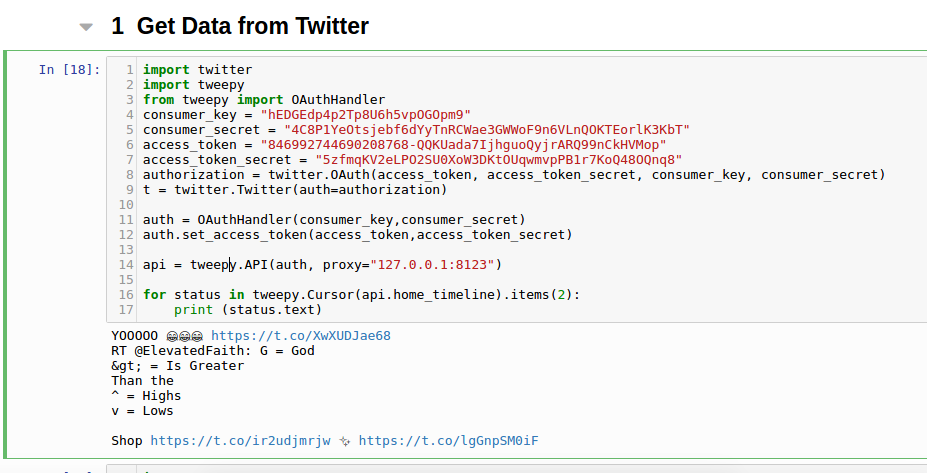
Python Tweepy 翻墙抓取Twitter信息
repo在此,如果觉得做得好,给个star鼓励下吧!
在看《Python数据挖掘入门与实践》的时候,随书附带的代码已经过时几年了,现在边看书边修,很是辛苦
在学习第六章”使用朴素贝叶斯进行社交媒体挖掘”时,数据集需要通过twitter的API来获取
(玛蛋,为毛不随书附带数据集)
twitter在国内被墙了,只能翻墙
浏览器翻墙容易,弄个lantern或者shadowsockets就可以了
但是,由于ubuntu的代理不是全局代理,在命令行中翻墙要设proxy,在代码中翻墙也要设proxy
所以难处在于代码要就twitter的python接口翻墙
如果只是一个简单的加proxy网络请求,几行就可以搞定:
1 | import urllib.request |
可是twitter的python接口是自动发起请求的呀
懒得去改源码
只好看看怎么在代码中设置好翻墙
账号准备
首先需要在twitter官方注册twitter账号,并新建一个应用,链接:新建应用
如果新建应用不成功,国内大多数情况都是无法验证手机号,可以参考这个教程,亲测有效,链接:验证手机号
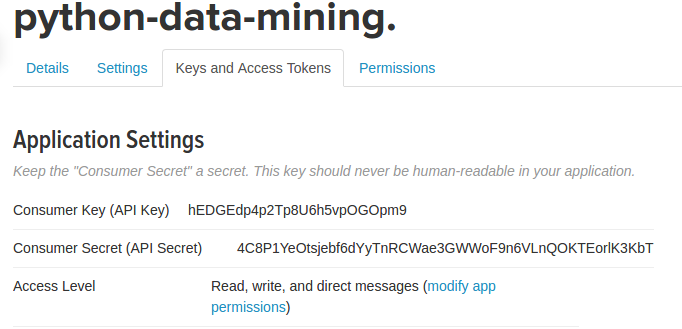
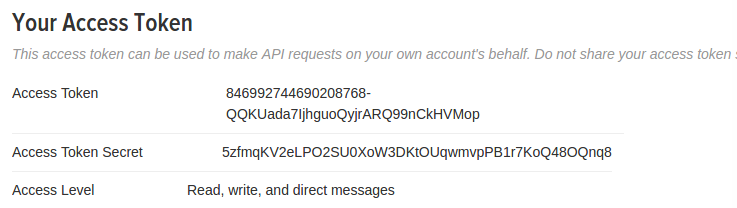
注册成功后,可以查看自己的keys and access token,如下图:
环境准备
python3.5+
安装tweepy: 在命令行中输入:pip install tweepy
发起请求
1 | # -*- coding: utf-8 -*- |
报错一:挂代理翻墙
报错信息如下:
1 | tweepy.error.TweepError: Failed to send request: HTTPSConnectionPool(host='api.twitter.com', port=443): Max retries exceeded with url: /1.1/statuses/home_timeline.json (Caused by ProxyError('Cannot connect to proxy.', NewConnectionError('<requests.packages.urllib3.connection.VerifiedHTTPSConnection object at 0x0000000002FC6E80>: Failed to establish a new connection: [Errno 10061] ',))) |
主要原因就是twitter被墙了,twitter的api当然也被墙了。
这时候就需要挂代理翻墙了,我使用的是自己搭建的shadowsockets。其它翻墙软件或者服务器网上有很多,请自行查找。
代理打开了之后,在原代码中,将1
api = tweepy.API(auth)
改为1
api = tweepy.API(auth,proxy="127.0.0.1:1080")
报错二:请求的配置没有写对
报错信息如下:
1 | tweepy.error.TweepError: Twitter error response: status code = 401 |
原因:
- 这几个发起请求的配置没有写对,仔细修改
- consumer_key
- consumer_secret
- access_token
- access_secret
- 改过了还是不对,刷新Regenerate Consumer Key and Secret和Regenerate My Access Token and Token Secret,重新填写请求
报错三
报错信息如下:
1 | tweepy.error.TweepError: Failed to send request: HTTPSConnectionPool(host='api.twitter.com', port=443): Max retries exceeded with url: /1.1/statuses/home_timeline.json (Caused by ProxyError('Cannot connect to proxy.', timeout('timed out',))) |
原因是Shadowsocks使用的是socks5代理,并非是http代理。
emmm,简单,大手一挥,稍微修改一下即可
1 | api = tweepy.API(auth, proxy="socks5://127.0.0.1:1080") |
报错四
报错信息如下:
1 | tweepy.error.TweepError: Failed to send request: SOCKSHTTPSConnectionPool(host='api.twitter.com', port=443): Read timed out. (read timeout=60) |
原因是tweepy使用的是http代理,不能用socks5代理(我日)。
所以需要将socks5代理转换为http代理来支持tweepy访问twitter REST API,这里参考以下地址:
为终端设置Shadowsocks代理
最后不要忘记在代码里加上代理:
1 | api = tweepy.API(auth, proxy="127.0.0.1:8123") |
还没完
tweepy 这个库的资料比较少,我自己摸索着试了试,把代码发上来
一.按照关键字搜索Twitter的内容
1 | #接上面的代码(q = 关键字 ,count = 返回的数据量 . 推特一次最多返回100条??) |
二.根据Twitter消息的ID批量获取消息1
2#其中id_list 是消息ID组成的list 长度也不要超过100
search_result = api.statuses_lookup(id_list)
这时,就可以成功访问了